Text-to-image customization, which aims to synthesize text-driven images for the given subjects, has recently revolutionized content creation. Existing works follow the pseudo-word paradigm, i.e., represent the given subjects as pseudo-words and then compose them with the given text. However, the inherent entangled influence scope of pseudo-words with the given text results in a dual-optimum paradox, i.e., the similarity of the given subjects and the controllability of the given text could not be optimal simultaneously. We present RealCustom that, for the first time, disentangles similarity from controllability by precisely limiting subject influence to relevant parts only, achieved by gradually narrowing real text word from its general connotation to the specific subject and using its cross-attention to distinguish relevance. Specifically, RealCustom introduces a novel “train-inference” decoupled framework: (1) during training, RealCustom learns general alignment between visual conditions to original textual conditions by a novel adaptive scoring module to adaptively modulate influence quantity; (2) during inference, a novel adaptive mask guidance strategy is proposed to iteratively update the influence scope and influence quantity of the given subjects to gradually narrow the generation of the real text word. Com- prehensive experiments demonstrate the superior real-time customization ability of RealCustom in the open domain, achieving both unprecedented similarity of the given subjects and controllability of the given text for the first time.
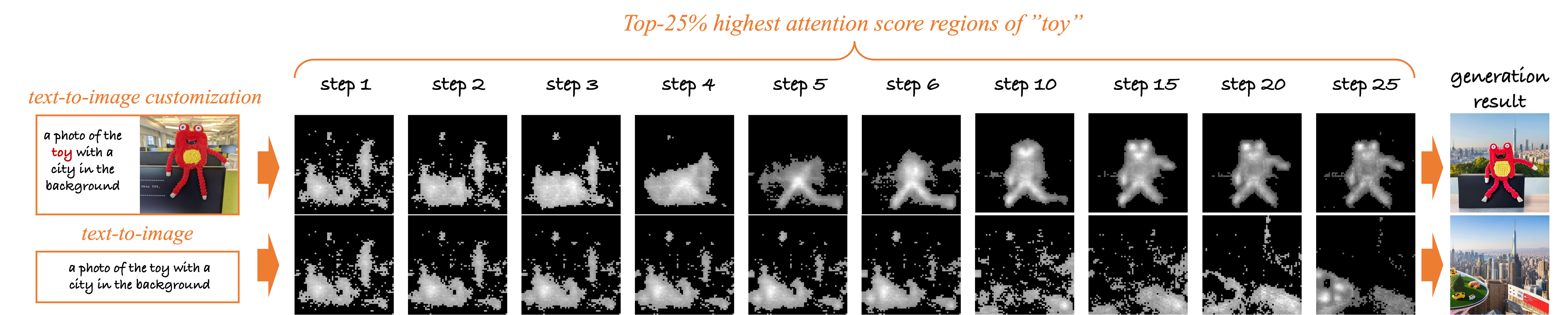
Core Idea: disentangle the influence scope of the given subject from the influence scope of the given text,
by precisely limiting the given subjects to influence only the relevant parts
while maintaining other irreverent ones purely controlled by the given texts,
achieving both high-quality similarity and controllability in a real-time open-domain scenario.
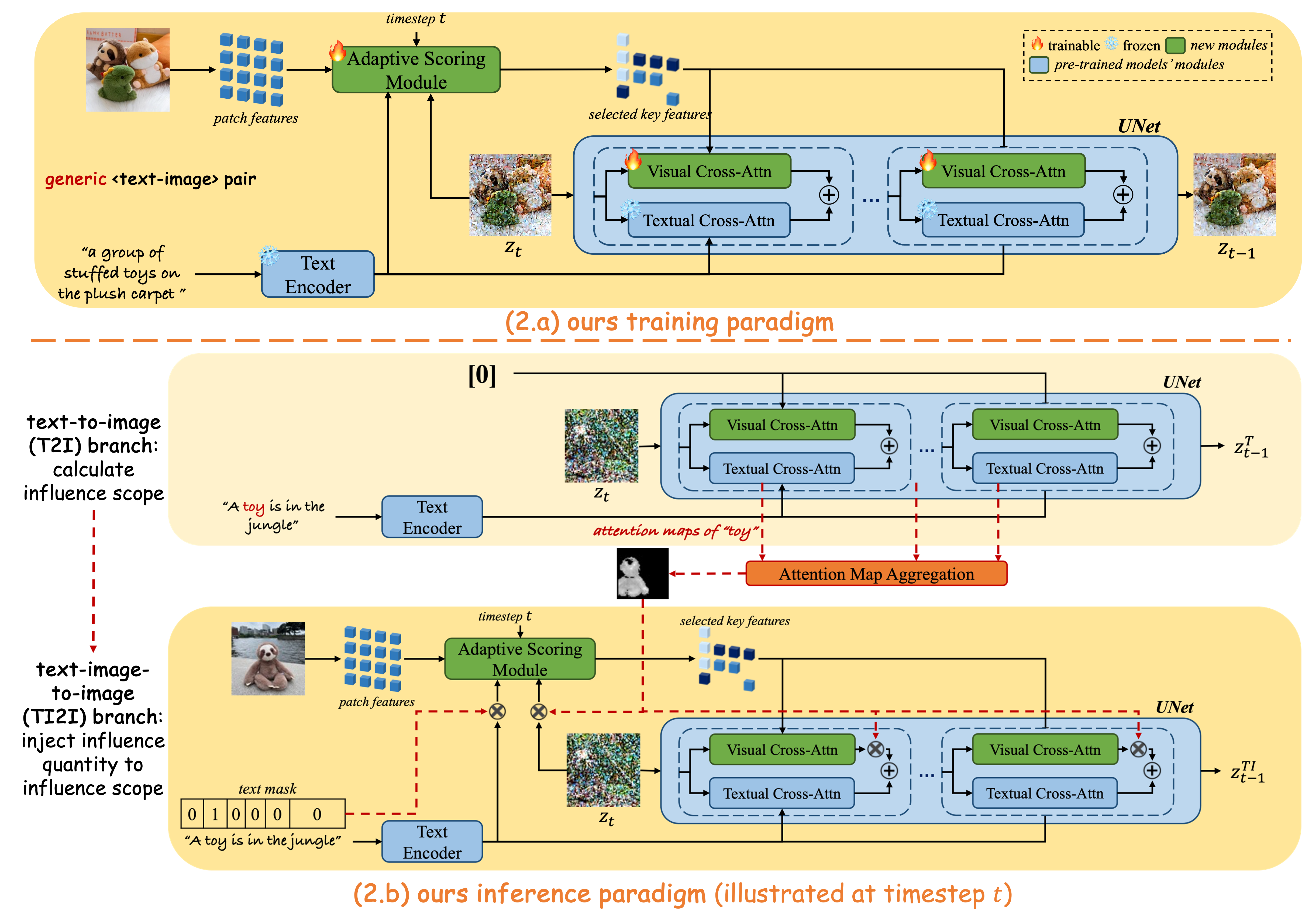
Training Paradigm:
RealCustom only learns the generalized alignment capabilities between visual conditions and pre-trained models'
original text conditions on large-scale text-image datasets through a novel adaptive scoring module,
which modulates the influence quantity based on text and currently generated features.
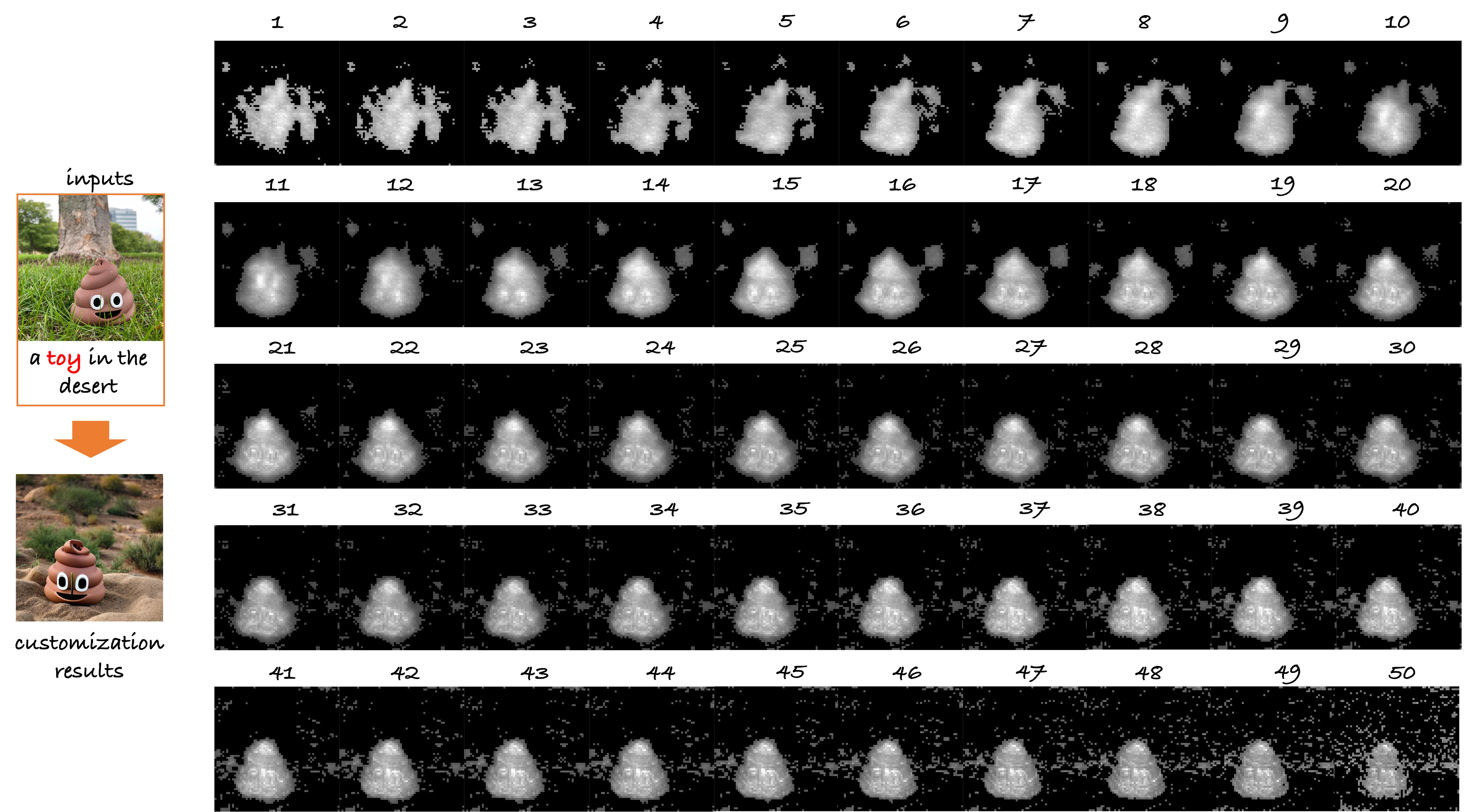
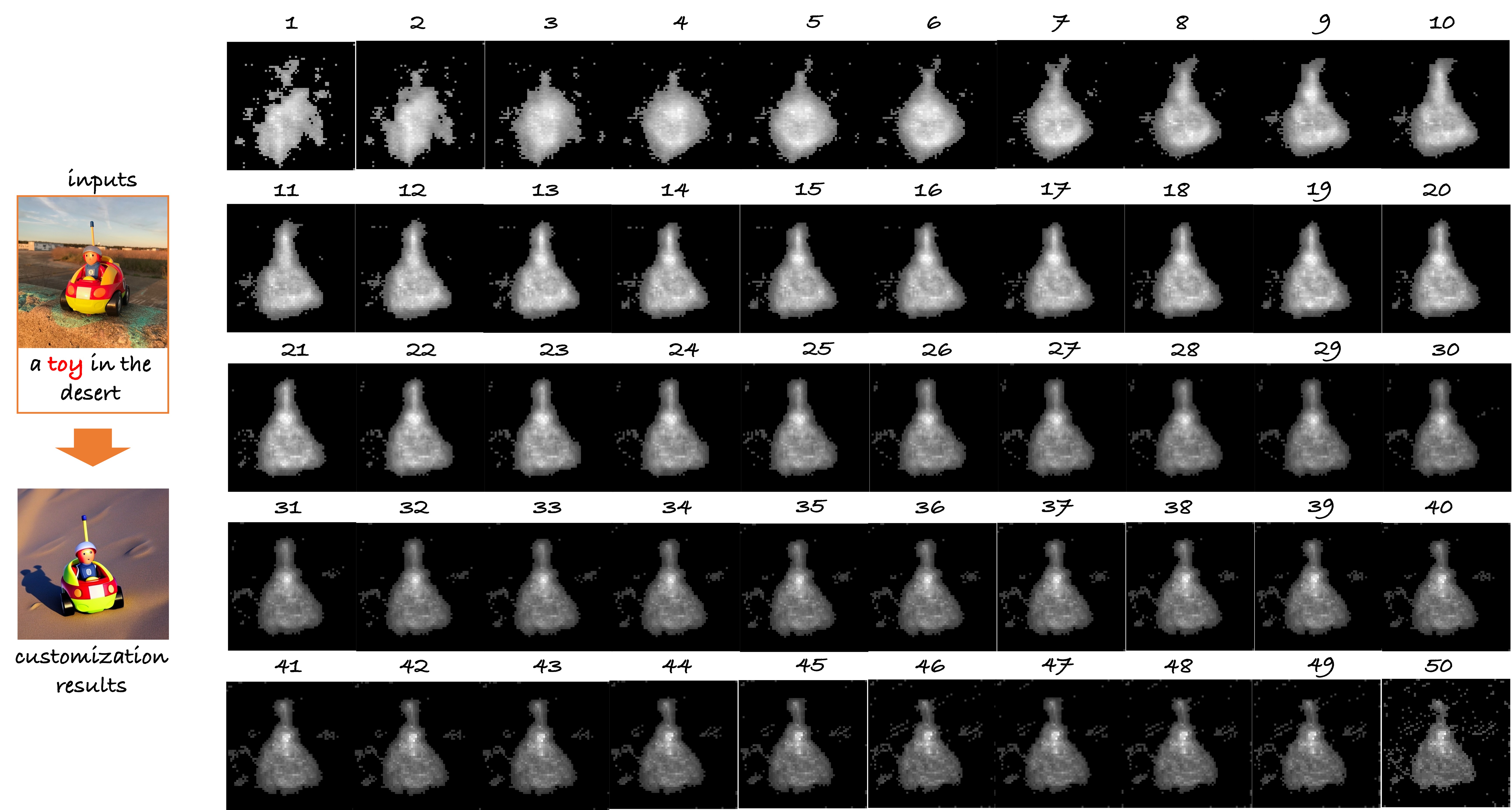
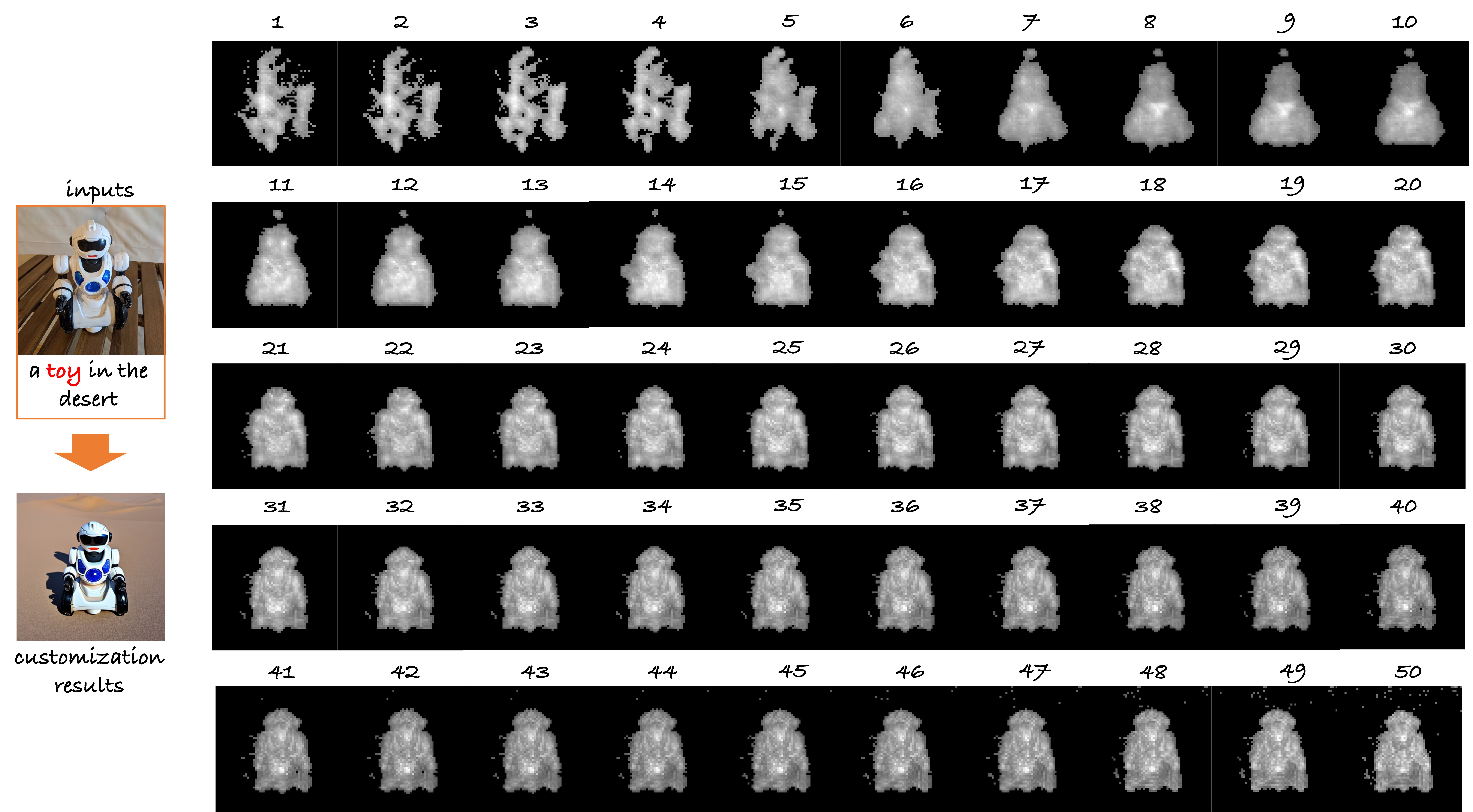
Inference Paradigm:
real-time customization is achieved by a novel adaptive mask guidance strategy,
which gradually narrows down a real text word based on the learned alignment capabilities.

RealCustom could produce much higher quality customization results that have better similarity with the given subject and better controllability with the given text compared to existing works. Moreover, RealCustom shows superior diversity (different subject poses, locations, etc.) and generation quality (e.g., the “autumn leaves” scene in the third row).